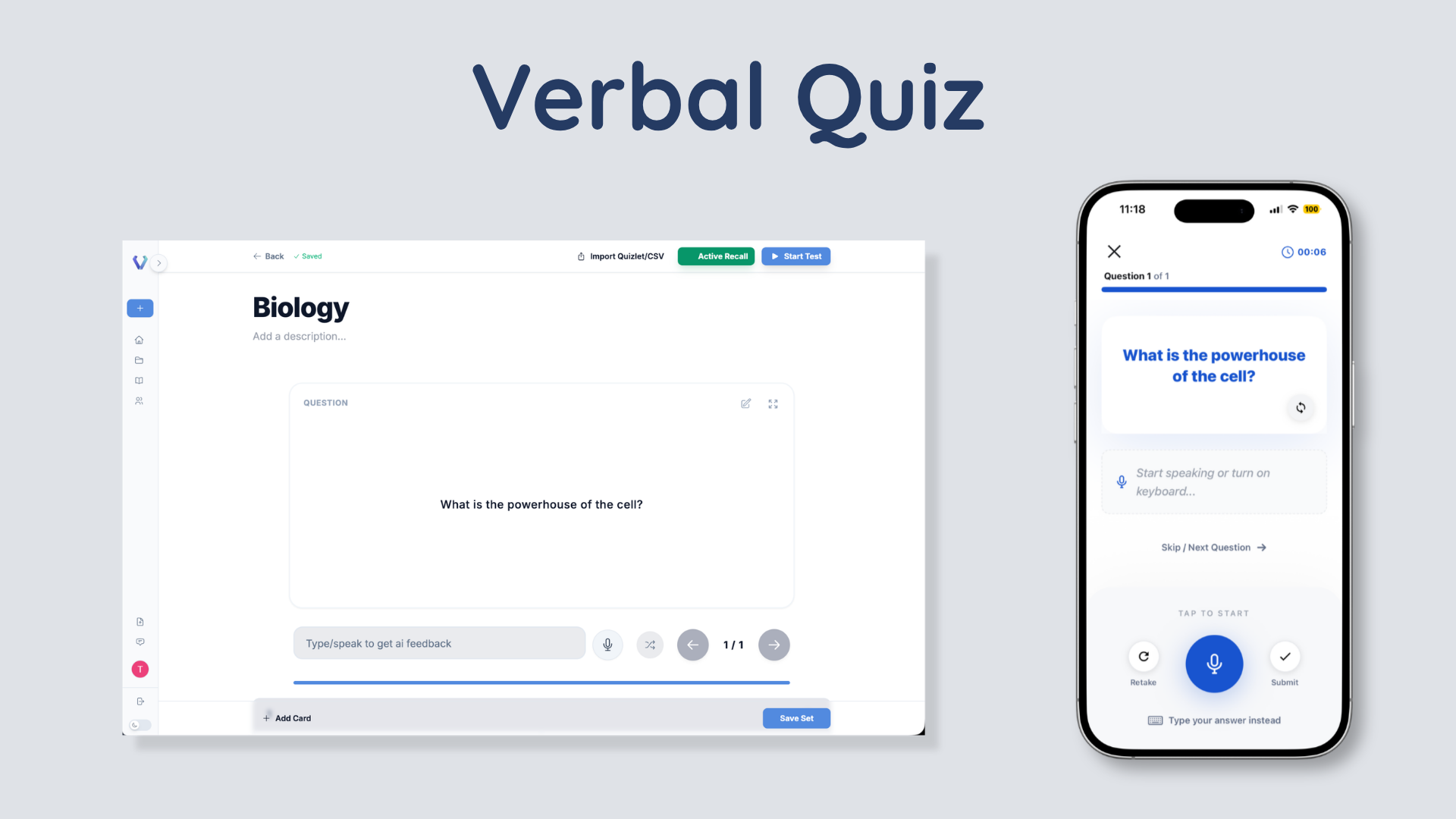
Traditional browser-based examinations rely on manual text inputs or multiple-choice interfaces. Verbal Quiz shifts this paradigm by executing full oral evaluations. The primary engineering hurdle lay in keeping voice transcription, semantic analysis, and follow-up audio queries below a natural 1.5-second conversational latency threshold.
GCAN resolved this by writing an asynchronous voice processing core running over FastAPI WebSockets. Audio input streams are chunked and dispatched to specialized inference endpoints, generating concurrent transcripts while downstream LLM rubrics prepare grading criteria and return text-to-speech payloads in parallel.
Audio Streaming
Compresses raw voice inputs locally using Opus codecs prior to transport.
FastAPI Sockets
Maintains persistent bi-directional connection channels for immediate response delivery.